
OCR with OpenCvSharp4
Peponi │ 7/16/2025 │ 6m
OCR with OpenCvSharp4
Peponi
1. Introduction
OCR (Optical Character Recognition) 은 이미지, 문서 내의 문자를 컴퓨터가 제어할 수 있도록 하는 기술이다. OCR을 통해 컴퓨터는 문서의 구조, 표, 수식 등과 함께 글자 정보를 확보하여 사용자에게 해석해주거나 수정 기능을 제공하는 등의 역할을 수행한다.
Tesseract는 이미지 파일에서 텍스트를 인식, 추출하는 데 사용하는 OCR 엔진이다. 영어 뿐만 아니라 한국어, 일본어, 중국어 등을 지원하며 각 언어에 대한 사전 훈련 데이터를 다운받는 것으로 간단하게 적용할 수 있다. 일반적으로 Tesseract는 다음 과정을 통해 텍스트를 인식한다.
- Preprocessing
텍스트 인식률을 높이기 위해 이미지 이진화, 노이즈 제거, orientation 수정 등을 진행한다. - Layout analysis
이미지 내의 텍스트 블록, 줄 등을 구분하여 분석할 텍스트의 위치를 파악한다. - Character recognition
패턴 매칭, LSTM 모델 등의 기법을 이용하여 텍스트를 인식한다. - Postprocessing
제공된 언어 모델을 활용하여 인식된 텍스트를 문맥에 맞게 수정한다.
이 문서에서는 OpenCvSharp4를 이용하여 전처리를 수행하고, Tesseract를 이용하여 OCR을 수행하는 간략한 예시를 알아본다.
C#에서 Tesseract를 사용하기 위해 먼저 Tesseract와 한국어 사전 훈련 데이터를 설치 후 Tesseract nuget package를 설치한다. (설치 경로는 다음 링크를 참조한다)
실습에 사용할 이미지는 다음과 같다.
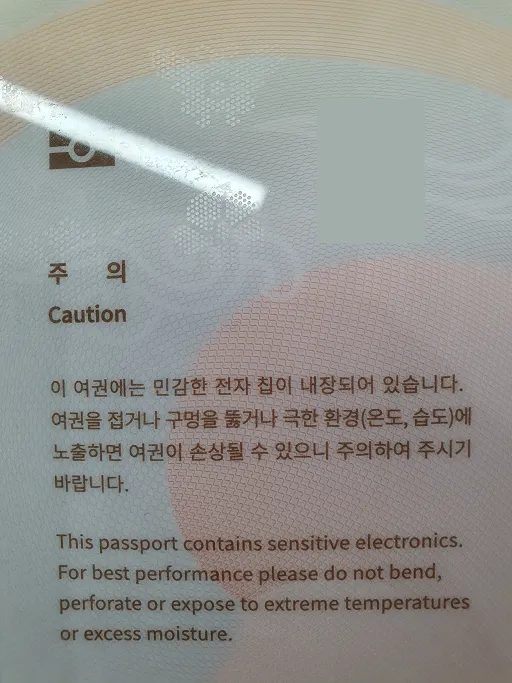
2. Example
각 언어를 지정하여 OCR을 수행한 결과는 다음과 같다.
 eng
engON
e 9
Caution
0} Of oh GZS AAt MO] ASLO} MWSLICt.
HAS BAU PAS SAL SS BASS, S=)ow
BHA YAO] SAH + NOL) Fo spot FAI7]
Urercicy.
This passport contains sensitive electronics.
For best performance please do not bend,
perforate or expose to extreme temperatures
or excess moisture.
 kor
kor7
주 의
63000
이 여 권 에 는 민 감 한 전 자 칩 이 내 장 되 어 있 습 니 다 .
여 권 을 접 거 나 구 멍 을 떠 나 극 한 환 경 ( 온 도 , 습 도 ) 에
노 출 하 면 여 권 이 손 상 될 수 있 으 니 주 의 하 여 주 시기
바 랍 니 다 .
가 15025500011001691715 디 9타 베 2( 타 에 히 65
『 아 665 카 011106 유 16356 00 101860
000120 아 076205 10 6712 621726
메 매 0655 015110
 kor+eng
kor+eng7
주 의
Caution
이 여 권 에 는 민 감 한 전 자 칩 이 내 장 되 어 있 습 니 다 .
여 권 을 접 거 나 구 멍 을 SAL 극 한 환 경 ( 온 도 , 습 도 ) 에
노 출 하 면 여 권 이 손 상 될 수 있 으 니 주 의 하 여 주 시기
바 랍 니 다 .
This passport contains sensitive electronics.
For best performance please do not bend,
perforate 아 expose to extreme temperatures
or excess moisture.
 eng+kor
eng+korON
주 의
Caution
이 여 권 에 는 민 감 한 전 자 칩 이 내 장 되 어 있 습 니 다 .
HAS 접 거 나 구 멍 을 SAL 극 한 환 경 ( 온 도 , 습 도 ) 에
노 출 하 면 여 권 이 손 상 될 수 있 으 니 주 의 하 여 주 시기
바 랍 니 다 .
This passport contains sensitive electronics.
For best performance please do not bend,
perforate or expose to extreme temperatures
or excess moisture.
private const string _tesseractPath = @"C:\Program Files\Tesseract-OCR\tessdata";
private void PerformWithVisualize(Mat image, string languageCode)
{
// Preprocessing
using var blur = image.CvtColor(ColorConversionCodes.BGR2GRAY)
.Threshold(100, 255, ThresholdTypes.Binary)
.GaussianBlur(new OpenCvSharp.Size(3, 3), -1);
// _tesseractPath 폴더의 languageCode.traineddata 불러와 Tesseract OCR 엔진 초기화
using var engine = new TesseractEngine(_tesseractPath, languageCode);
// OCR 수행
// region : OCR을 수행할 영역
// pageSegMode : 사용할 분할 알고리즘 설정
using var data = engine.Process(Pix.LoadFromMemory(blur.ToBytes()));
// 결과 출력
Debug.WriteLine($"Start writing text - Language code : {languageCode}");
Debug.WriteLine($"Text :{Environment.NewLine} {data.GetText()}");
Debug.WriteLine($"Mean confidence : {data.GetMeanConfidence()}");
// 결과 표시
var result = blur.CvtColor(ColorConversionCodes.GRAY2BGR);
using var iterator = data.GetIterator();
iterator.Begin();
do
{
string word = iterator.GetText(PageIteratorLevel.Word);
// 단어 영역의 박스 얻기
if (iterator.TryGetBoundingBox(PageIteratorLevel.Word, out var bound))
{
// 문자 인식 영역 사각형 그리기
result.Rectangle(new OpenCvSharp.Rect(bound.X1, bound.Y1, bound.Width, bound.Height), Scalar.MediumSeaGreen);
// OpenCV는 utf-8 텍스트 지원이 되지 않기 때문에 직접 그림 (영문은 Cv2.PutText() 메서드 사용해도 무방)
using var textTarget = result.ToBitmap();
using var graphic = Graphics.FromImage(textTarget);
graphic.DrawString(word, new Font("Consolas", 10), Brushes.Crimson, new PointF(bound.X1, bound.Y1 + bound.Height + 1));
// 이전 객체 dispose 후 새로 할당
result.Dispose();
result = BitmapConverter.ToMat(textTarget);
}
}
while (iterator.Next(PageIteratorLevel.Word));
Cv2.ImShow($"{languageCode} result", result);
}